Just like DeepSeek, Kimi K2 is open-source. But unlike DeepSeek, it’s not a reasoning model; it instead excels in agentic tasks. It doesn’t just tell you what to write or how to solve a problem; it writes the code, executes the tasks, and gets stuff done. While most AI models answer questions and offer suggestions through chat interfaces, Kimi K2 was designed from the ground up to go beyond these standards.

In this article, we will look at how we can integrate Kimi K2 agentic mode into an application. We’ll discuss how it’s different from DeepSeek, and might more closely relate to Claude Code.
In the course of this article, I will use K2, Kimi and Kimi K2 interchangeably.
Kimi K2 vs. DeepSeek
Before diving into the comparison, let’s understand what Kimi K2 actually is. Kimi K2 is a state-of-the-art mixture-of-experts (MoE) language model with 32 billion activated parameters and 1 trillion total parameters developed by China’s Moonshot AI:

Unlike reasoning models that can afford to “think slowly,” agents need to act much faster and efficiently. By activating only 32 billion out of 1 trillion parameters (about 3.2%), Kimi K2 can:
- Respond faster — Less computation per token means quicker responses
- Use less memory — Only the active experts need to be loaded for inference
- Scale better — Can handle more concurrent requests with the same hardware
What exactly makes Kimi K2 effective at execution? The model uses 384 distinct experts, with eight being selected to process each token, allowing for highly efficient computation. More importantly, it was trained with the MuonClip optimizer, achieving pre-training of a 1T parameter MoE model on 15.5T tokens with zero training instability.
DeepSeek R1, conversely, demonstrates that the reasoning capabilities of LLMs can be incentivized purely through RL, without the need for SFT. It’s trained to think deeply about problems, which is why R1-0528 benefits from great reasoning depth, averaging 23,000 tokens per question.
When to use each model
Despite K2 beating DeepSeek on SWE-bench (43.8% vs 12.8%), you do not want to use K2 on problems that DeepSeek thrives on better. Below are details on when to use either of the two models efficiently:
Choose DeepSeek R1 when you need:
- Deep mathematical reasoning
- Complex logical analysis
- Tasks where thinking time improves outcomes
- Academic or research applications requiring thorough exploration
Choose Kimi K2 when you need:
- Real-world code implementation and debugging
- Native tool integration and API calling
- Autonomous task execution
- Production workflows requiring consistent results
- Applications where speed and reliability matter more than perfect reasoning
- 5x cheaper than Claude/GPT while matching performance
Here is a table that highlights the differences:
| Feature | Kimi K2 | DeepSeek Coder | Claude 4 Sonnet |
|---|---|---|---|
| Cost per 1M tokens | $0.15 / $2.50 | $0.07 / $1.10 | $3 / $15 |
| Context Length | 128K tokens | 128K tokens | 200K tokens |
| SWE-bench Score | 43.8% | 12.8% | 67.6% |
| Key Strengths | Agentic execution, native tool use, 5x cheaper than Claude | Low cost, deep reasoning, open source | Balanced excellence, enterprise reliability |
| Best Use Cases | Production workflows, autonomous tasks, real-world implementation | Budget-conscious teams, research, complex reasoning | General development, majorly for enterprise applications |
Why this matters for frontend developers
Here’s the thing: The technical benchmarks are impressive, but what does this mean for you as a frontend developer?
If you need to refactor 200 components from class to hooks? K2 handles the entire codebase migration while maintaining functionality. Converting your design system from React to Vue? It’ll knock that out too, complete with proper TypeScript definitions.
But here’s where it gets interesting. K2 doesn’t just write code; it structures your workflows as well. Given the right tool, it can take your Figma design where it extracts design tokens, generates responsive components, writes the tests, and handles deployment. All automated.
Instead of manually fixing webpack configs and bundle analyzers, K2 implements lazy loading and validates improvements while you’re building features.
You get an AI that executes rather than only suggests. Let’s see how this Kimi works in our frontend going forward.
Getting started with Kimi K2
You can access Kimi through four different channels: the web interface, AI-powered IDEs, self-hosting, and their API.
The web interface is where you’ll find their free and open chat interface, pretty generous of them, actually. For IDEs like Windsurf, you can integrate Kimi directly into your development workflow. Through their API, you can connect it with OpenRouter or use the Qwen CLI to access their agent capabilities.
Web
Kimi K2 is available at no cost through kimi.com for both web browsers. The platform is currently developing MCP (Model Context Protocol) integrations, a standard that allows AI models to securely connect with external data sources and tools:
In an IDE
We can also use this on Windsurf Premium. Just select the model, and Windsurf uses it side by side for autonomous tasks:
Self-hosting
Organizations preferring to run K2 on their own infrastructure can deploy it using several inference engines: vLLM (optimized for large language models), SGLang (structured generation language), KTransformers (Kubernetes-based transformers), or TensorRT-LLM (NVIDIA’s optimized runtime). Setup instructions are provided in the project’s GitHub repository.
Developer API integration
The Kimi platform provides API compatibility with both OpenAI and Anthropic standards, making it straightforward to integrate K2 into existing applications without major code changes.
With the free tier: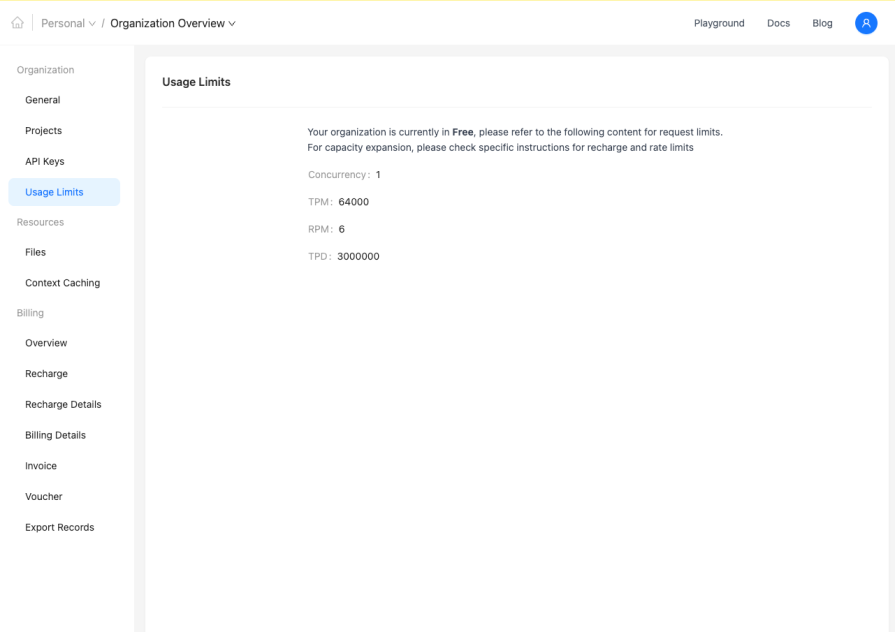
Concurrency: 1
You can only make 1 simultaneous API request at a time. If you send a second request while the first is still processing, it will be queued or rejected. This is quite restrictive for production use
TPM: 64,000
You can process up to 64,000 tokens per minute. This includes both input tokens (your prompts) and output tokens (the model’s responses). For context: a typical conversation might use 500-2000 tokens
RPM: 6
Only 6 API calls are allowed per minute. This is very low – means you can only make one request every 10 seconds. Major bottleneck for any real application
TPD: 3,000,000
Users recieve 3 million tokens maximum per day. This is actually quite generous for a free tier. Equivalent to roughly 1,500-6,000 typical conversations per day
The reality check
The RPM limit of 6 is probably why you will want to put a little cash; something as little as $3 will take you so far. Even with 3 million tokens per day available, you can only access them 6 requests at a time per minute. This makes the free tier suitable for:
- Testing and experimentation
- Small personal projects
- Proof of concepts
The free tier, however, is completely inadequate for production applications and any serious development work. This is a popular “freemium” strategy, giving you enough to try the service and see its potential, but forcing you to upgrade for any meaningful usage. You can’t blame these AI providers; it costs a lot to run things of this sort.
Setting up Kimi K2 API
You can use Kimi K2 through OpenRouter. OpenRouter is a service that provides a unified API access to multiple LLMs, including Kimi K2. OpenRouter acts as a gateway that lets you access various AI models through a single API endpoint.
Ensure you have an OpenRouter account (for unified API access) or a Moonshot account (for direct access).
Step 1: Get Your API Key
Option A – OpenRouter (Recommended for beginners):
- Go to openrouter.ai
- Sign up for free account
- Navigate to API Keys section
- Generate new API key (starts with
sk-or-v1-)
Option B – Direct Moonshot (Faster, potentially cheaper):
Go to platform.moonshot.ai
Navigate to the API Keys:
Create an API key and save it somewhere safe.
Step 2: Install Claude Code Router
# Install globally from npm (not from GitHub) npm install -g @musistudio/claude-code-router
Note: Don’t clone from GitHub – the published npm version works better.
Step 3: Start and configure
ccr start
You’ll be prompted for configuration. Choose your approach:
Option A – Using OpenRouter
Provider name: openrouter API base URL: https://openrouter.ai/api/v1 API key: sk-or-v1-your-actual-key-here Model name: moonshotai/kimi-k2
Option B – Direct Moonshot
Provider name: moonshot API base URL: https://api.moonshot.ai/anthropic API key: your-moonshot-api-key Model name: kimi-k2
Step 4: Verify setup
After configuration, you should see:
openrouter provider registered (or moonshot provider registered) 🚀 LLMs API server listening on http://127.0.0.1:3456

Step 5: Test your setup
Command line:
ccr code "Write a Python function to read CSV files"
Troubleshooting common issues
Command not found
You may fall into a ccr command not found error. To fix this:
- Make sure you installed globally:
npm install -g @musistudio/claude-code-router - Check Node.js is installed:
node --version
Router not finding your config
The config is stored in ~/.claude-code-router/config.json.
Edit this file directly if needed using the command below:
open ~/.claude-code-router/config.json
Adding multiple providers
Edit ~/.claude-code-router/config.json:
{
"LOG": false,
"OPENAI_API_KEY": "",
"OPENAI_BASE_URL": "",
"OPENAI_MODEL": "",
"Providers": [
{
"name": "openrouter",
"api_base_url": "https://openrouter.ai/api/v1",
"api_key": "sk-or-v1-your-key",
"models": ["moonshotai/kimi-k2"]
},
{
"name": "moonshot",
"api_base_url": "https://api.moonshot.ai/anthropic",
"api_key": "your-moonshot-key",
"models": ["kimi-k2"]
}
],
"Router": {
"default": "moonshot,kimi-k2",
"fallback": "openrouter,moonshotai/kimi-k2"
}
}
Why this setup works
Claude Code Router acts as a local proxy. Your API key authenticates you with the provider (OpenRouter or Moonshot). The provider forwards requests to Kimi K2. You get billed through your chosen provider. Any Claude-compatible tool can now use Kimi K2 instead.
Qwen CLI
The Qwen CLI is designed with a focus on code-aware conversations and agentic interactions. While it is primarily associated with the Qwen models from Alibaba Cloud, it offers flexibility in integrating with other AI providers, especially those that provide an OpenAI-compatible API. Remember, earlier we said the Kimi API is very compatible with OpenAI.
First, install Qwen CLI:
npm install -g @qwen-code/qwen-code
Skip this export
export OPENAI_API_KEY="your_api_key_here"
export OPENAI_BASE_URL="https://openrouter.ai/api/v1"
export OPENAI_MODEL="qwen/qwen3-coder:free" # Or the specific model you want to use from OpenRouter
After installation, run qwen, and you will be asked to set up authentication:
Navigate to your OpenRouter account, and create an API key for Kimi: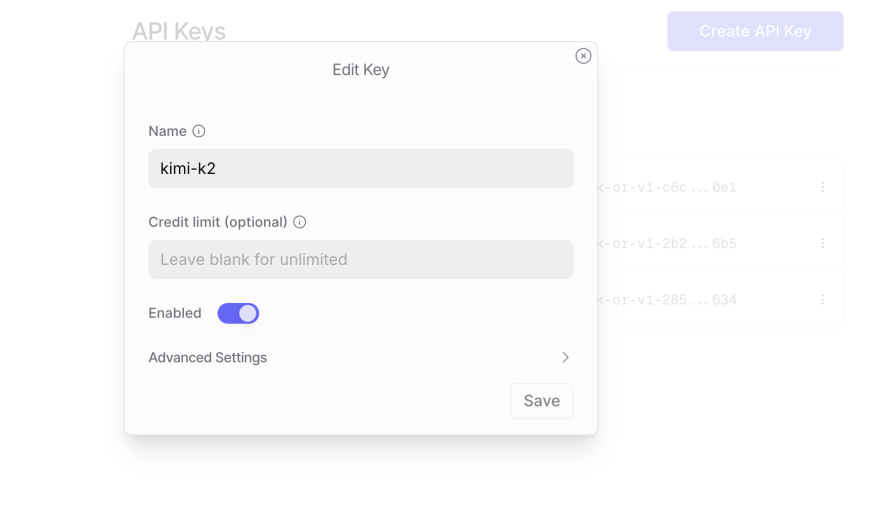
Copy the key, and keep it safe: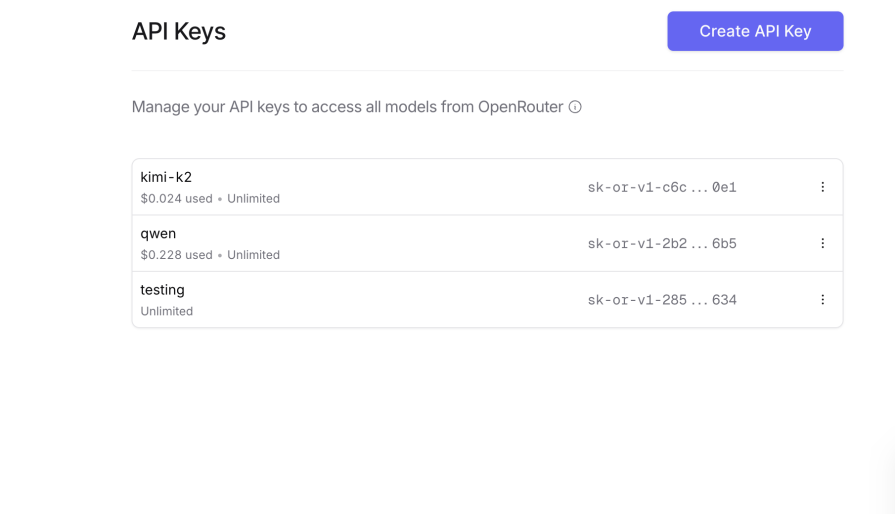
And now authenticate Qwen using these keys obtained from OpenRouter:
API Keys- YOUR-API-KEY Base URL- https://openrouter.ai/api/v1 Model- moonshotai/kimi-k2
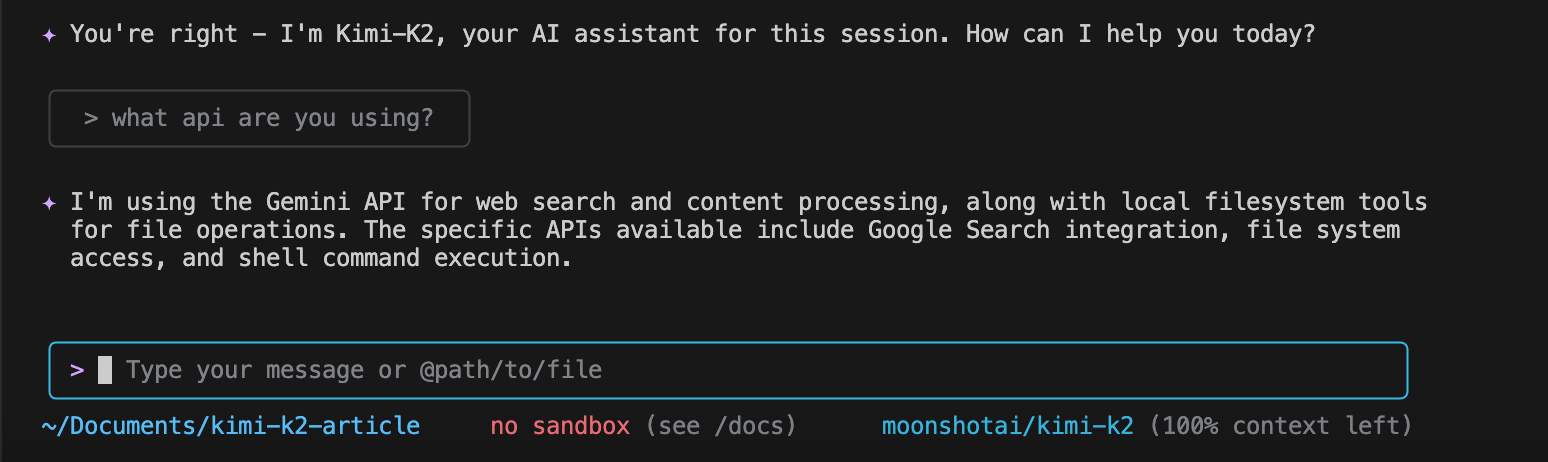
We can see it is using the Kimi K2 API:
Here is how much credit has been used so far, with the little conversation we had about why it really was underneath the hood: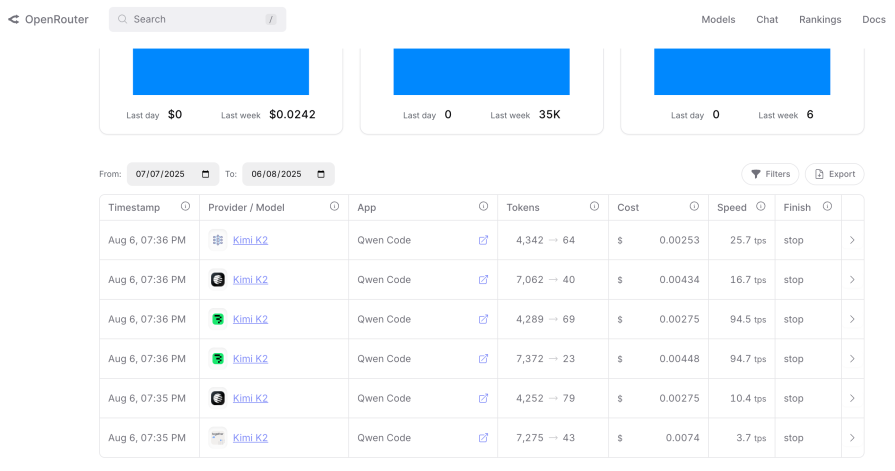
Frontend design test with Kimi K2, Claude, and Deepseek
I conducted two simple frontend tests. First, I am asking these models to recreate my portfolio site. It looks simple, but the truth is, these models usually don’t do the best at replicating designs. In fact, they recreate it with their pattern. For the second test, I asked Kimi to build a Svelte 5 application. Let’s see how it performs.
Here is the prompt:
I have attached my portfolio site's code below: //I included my project code using next.js Recreate https://marvel-ken.vercel.app/ homepage with: Exact design, animations, and layout Light/Dark/System theme modes with toggle Smooth theme transitions Single HTML file (embedded CSS/JS) No external libraries Responsive design Remember theme preference Add enhanced hover effects and improved visual polish.
DeepSeek
Here is what DeepSeek produced. In truth, it had to do this three times to get the final result: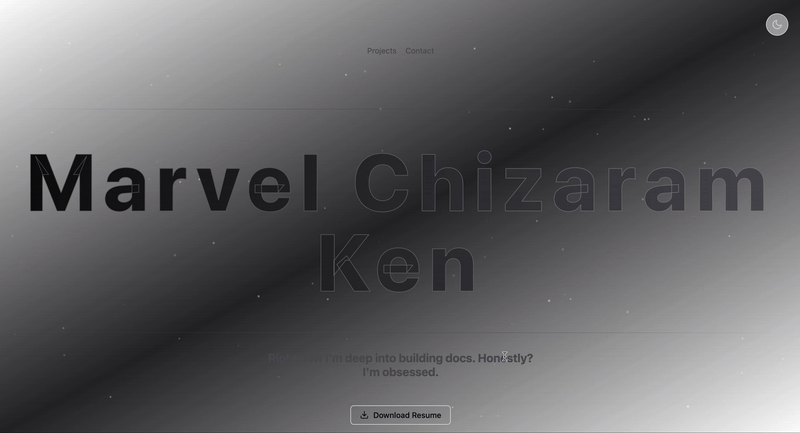
Claude
Claude did exceptionally well; it even went beyond what was asked:
Kimi K2

Kimi K2 and Claude’s results were much better.
Svelte test
Here we will be testing it using Svelte 5, as AI models are very React-friendly and may not find it comfortable on this neutral ground. Since most of what you’ll be doing is CRUD operations, a todo application with Firebase integration will be perfect for testing.
The prompt was:
Create a complete todo application using Svelte 5 and Firebase, with custom SVG icons and smooth animations throughout.:
The shocking result
Kimi K2 one-shotted this application. This is insane because both DeepSeek and Qwen couldn’t nail it on the first trial, and it only cost $0.471 with a total of 425k tokens, very much affordable.
I can now believe it’s actually a very reliable agentic model, and honestly, it’s good at coding. I like the fact that it takes its time to articulate prompts properly instead of rushing through responses.
Kimi K2: Complete feature overview
Moonshot AI’s latest open-source model that’s outperforming GPT-4 on key benchmarks while being fully accessible to developers:
| Category | Features |
|---|---|
| Architecture | 1T total parameters, 32B activated (MoE), 130k context window. MuonClip optimizer with zero training instability |
| Performance | 53.7% LiveCodeBench (vs GPT-4.1’s 44.7%). 97.4% MATH-500 (vs GPT-4.1’s 92.4%). 65.8% SWE-bench Verified |
| Agentic Intelligence | Native tool use and API integration. Autonomous problem-solving. Multi-step workflow automation |
| Availability | Open weight with local deployment. API: $0.60 input, $2.50 output per 1M tokens. Two variants: Base and Instruct |
| Use Cases | Advanced coding & debugging. STEM problem-solving. Research with long context Automated agentic workflows |
Current limitations
According to the team, internal testing has revealed several areas for improvement:
- The model sometimes generates excessive text when handling complex reasoning tasks or working with poorly defined tools, potentially causing incomplete responses.
- Performance may also decrease on certain tasks when tool integration is active.
- For comprehensive software development projects, iterative prompting within an agentic framework tends to outperform single-prompt approaches.
The development team is actively addressing these issues based on user feedback.
Conclusion
Kimi-K2 represents “AI that acts.” With its free access available and superior agentic capabilities, now is the time to experiment and integrate. Early adopters could easily choose to give their money when prices are advancedly fixed.
References